Introduction
AI programming is undergoing a profound transformation, with distinct paths emerging in technology development.
Recently, the tech community was stirred by the announcement from Cursor co-founder Wilson Lin: “Building a browser from scratch using AI agents, generating 3 million lines of code in a week.” However, this ambitious attempt ended in failure: the generated code could not be compiled, lacked basic interface coordination between modules, had severe architectural deficiencies, and achieved almost no functional implementation, leading to widespread ridicule as “AI slop.”
Yet, this debacle was not the end. While Cursor’s dream of a “software factory” crumbled, a Chinese team took a different technical route and quietly achieved what was previously thought impossible: generating a commercial-grade C compiler in just 10 days using a new programming language, with performance close to industry benchmarks.
From an external perspective, this is not merely about “AI writing a compiler”; it showcases a relatively stable and sustainable method of “building software with AI.” In other words, the importance lies not in a one-time generated result but in a self-sustaining, continuously optimizable engineering curve.
If this path is not a coincidence but can be systematically replicated, then the AI automated production line built on reusable engineering mechanisms has significant implications for the entire software engineering field.
Synthesizing a C Compiler with AI
Technical Implementation Process
The MoonBit team is a leading force in the domestic AI programming language sector and the only team in China capable of rapidly deploying industrial-grade languages and toolchains (with global counterparts like Google, Microsoft, and Apple). Led by Zhang Hongbo, chief scientist at the IDEA Institute, they designed the MoonBit language specifically for AI and cloud-native scenarios, supporting multi-backend compilation with outstanding performance. Currently, MoonBit is used in courses at Tsinghua University, Peking University, and has been adopted by overseas cloud service providers, with over 100,000 core users and nearly 4,000 libraries. By the end of 2026, it is projected to have tens of thousands of libraries, matching the ecosystem of Apple’s Swift.
MoonBit has not only accumulated a large user base domestically but has also gained widespread recognition abroad, particularly in the Japanese tech community and on X (formerly Twitter), where numerous technical discussions about MoonBit are emerging. Many developers are contributing to its ecosystem on GitHub, with a notable Japanese tech influencer stating: “Once people realize the value of MoonBit, they will flock to it.”
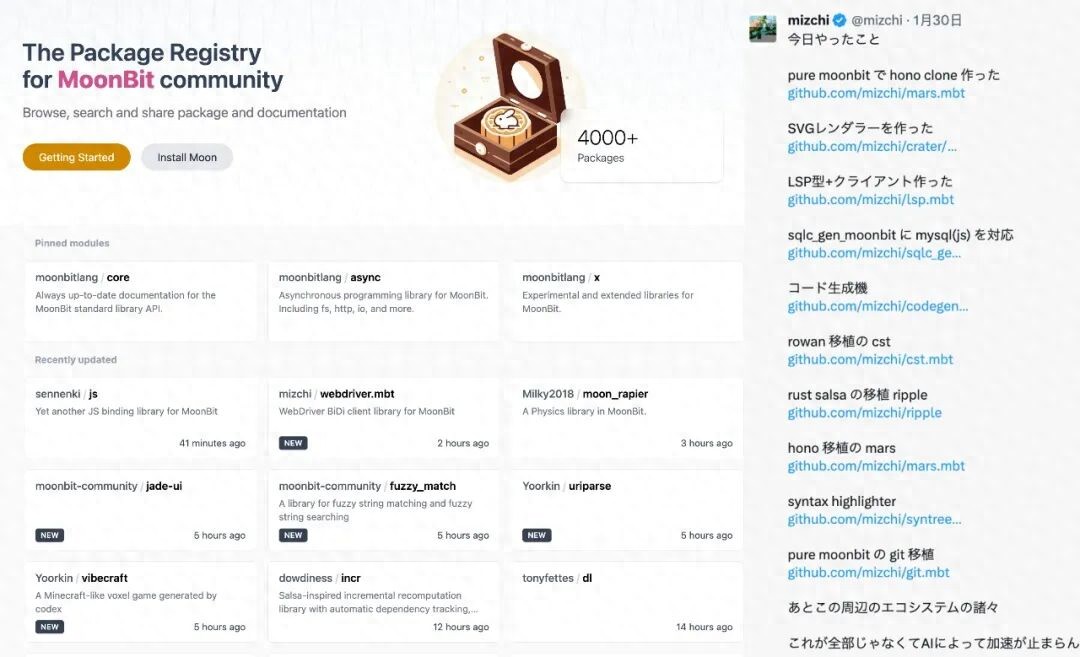
Recently, the MoonBit team announced breakthrough progress in the “AI software factory,” demonstrating the potential for efficiently replicating large software projects with better quality and reliability. Importantly, this is not just about one-time code generation but a repeatable and verifiable software production process.
Thanks to the rapid advancement of large models, the speed and quality of AI-produced software have significantly improved. The production speed of a standard large software project, typically around 35,000 lines of code, has increased from approximately 100 days to a year down to less than 10 days. We now have reason to believe that most software in the future will be produced through automated software factory pipelines.
However, crossing several key nodes in the production process is not easy, specifically the 60% and 90% nodes. For example, Cursor’s generated browser reached 60%, but failed to progress to 90%. The reason lies in Cursor’s lack of mastery over programming languages, AI-native toolchains, and testing capabilities.
Trends in Software Factory Production
Using the C compiler as an example, here are real software production cases from the MoonBit team:
Other examples publicly showcased by the “MoonBit AI Software Factory”:
- PDF Tool: https://github.com/moonbitlang/mbtpdf
- wasm Compiler: https://github.com/Milky2018/wasmoon
- JavaScript: https://github.com/Lampese/NocturneJS
- d2ang: https://github.com/moonbit-community/diago
- …
We set a challenging goal: to build a C compiler from scratch.
The initial aim was to explore the boundaries of AI’s capabilities, attempting to let AI complete a large software project with nearly zero intervention.
Traditionally, building a fully compliant C compiler from scratch is considered a high-difficulty task, involving lexical analysis, syntax parsing, semantic checking, optimization, and code generation, requiring deep knowledge of compiler principles and hardware architecture, often taking months or even years to complete.
The entire process felt like a science fiction novel. I put on my headphones, activated voice mode, and instructed the AI: “Build a C compiler from scratch, close to tcc, supporting arm64 architecture.”
The choice of tcc as an example is because it is the fastest C compiler in the world, and compilation speed is particularly important for the MoonBit development experience. The native backend supports both LLVM and C; if the C backend has its own compiler, it can achieve complete self-bootstrapping. Moreover, tcc is unsafe, lacks maintenance, and has optimization alternatives. To quickly validate, we only let the AI support the arm64 architecture.
By the seventh day, it had already achieved self-bootstrapping. Here, self-bootstrapping means first using the Moon toolchain to build Fastcc.mbt (the project name), generating Fastcc.exe, and then using Fastcc.exe to compile the Fastcc.mbt code generated by the Moon toolchain into C code, producing Fastcc1.exe. Finally, Fastcc1.exe is used to execute tests on Fastcc.mbt to verify correctness. It could also compile the source code of tcc, using v.c (a single C file snapshot of the vlang compiler) to test compilation performance, where the gap with tcc was 60x (meaning Fastcc.mbt was 60 times slower than tcc).
By the tenth day, I had hardly used the keyboard. The agent autonomously decomposed tasks: first designing the AST (abstract syntax tree), generating basic modules; then optimizing performance using a multi-pass approach instead of directly copying tcc’s single-pass structure—despite the prompt requesting “close to tcc,” the AI chose a more reliable path.
During breaks from daily work, I would check the AI’s progress, occasionally needing to make some corrections and instructions: the AI autonomously used lldb to debug and locate bugs, called Xcode command-line tools for performance analysis under guidance, and wrote scripts to identify hotspot code for targeted optimization. On the seventh day, a surprise occurred—the compiler successfully self-bootstrapped: first using the MoonBit toolchain to generate Fastcc.exe, then using it to compile its own code, passing the tests.
Throughout the process, the AI operated like a tireless team of excellent programmers, smoothly functioning within the MoonBit ecosystem. Ultimately, in 10 days, 35,000 lines of code were generated by the agent, with high readability.
It is worth noting that this was not a coincidence but a deterministic result of the MoonBit software factory’s toolchain and language design.
The next natural evolution of the “MoonBit Software Factory” is to solidify the successful engineering processes into a repeatable software production capability. Once this capability stabilizes, it will no longer be limited to compilers but can be extended to more software categories—from foundational libraries and toolchain components to systems closer to business sides. When such production capacity begins to scale, it may herald a new era.
From AI Writing Code to “Software Factory”
Technical Architecture Analysis
The reasons why MoonBit improved software completion rates from 60% to 100% include the following:
Language Design
The MoonBit language establishes the core concept of “AI native,” discarding complex syntactic structures that serve human habits but burden AI understanding, such as nested scopes, implicit type conversions, and overloading mechanisms.
It adopts a “flattened” syntax design with extremely simple syntax rules, highly clear semantic expressions, and powerful static type systems. All language features undergo systematic evaluation for AI understandability and generation friendliness, ensuring that the model does not produce errors due to ambiguity during reasoning. This design significantly reduces the ambiguity costs for large models in semantic parsing, contextual inference, and code generation processes, greatly enhancing the accuracy, consistency, and predictability of generated results.
Additionally, the language inherently supports AI feedback mechanisms, such as type hint injection, error localization markers, and natural language comment mapping, allowing natural language requirements to be efficiently and accurately converted into executable code, significantly improving the transformation from “intention to code.”
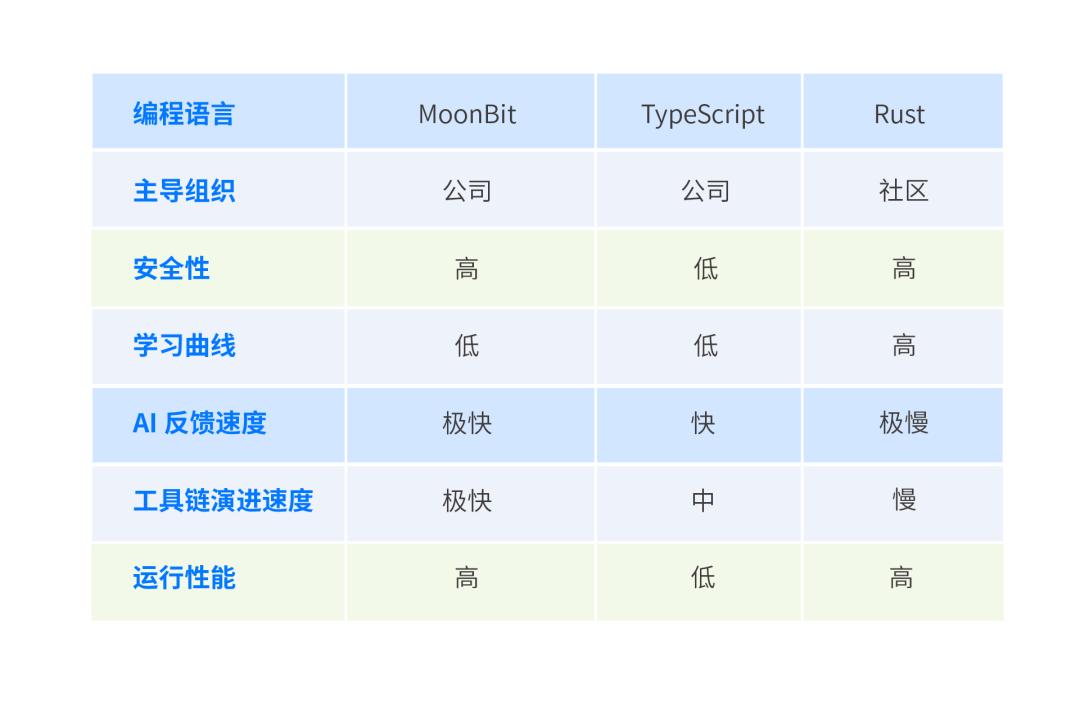
MoonBit’s runtime performance is on par with Go and Swift and even outperforms them in certain scenarios. In public benchmark tests, MoonBit’s compilation speed is 10 to 100 times faster than Rust.
Correspondingly, the feedback speed of the MoonBit software factory is extremely fast. In AI software production scenarios, compared to the past where human-written code required compilation speed, AI can now run thousands of compilations a day, making compilation speed crucial, further highlighting the advantages of MoonBit software engineering.
AI Safe Refactoring
When producing or refactoring software in the software factory, the MoonBit toolchain does not allow AI to modify code blindly; instead, it provides a callable and verifiable refactoring infrastructure for agents.
moon ide is an IDE tool designed for AI agents, covering capabilities such as definition jumping, reference searching, renaming, structure analysis, and documentation querying. These interfaces are not “functions for humans” but are directly exposed to agents using a stable, parsable command-line protocol.
For example, in the rename function, moon ide rename does not generate vague text replacement results but directly outputs structured patches that comply with OpenAI Codex’s apply_patch specification. In other words, renaming no longer relies on the model guessing context but is provided by the toolchain with defined modification ranges and precise change results.
This brings several direct benefits:
- Refactoring is based on semantics and symbol tables rather than string matching.
- Modification boundaries are clear, avoiding structural drift.
- Each change can immediately enter the compilation, testing, and static analysis verification processes.
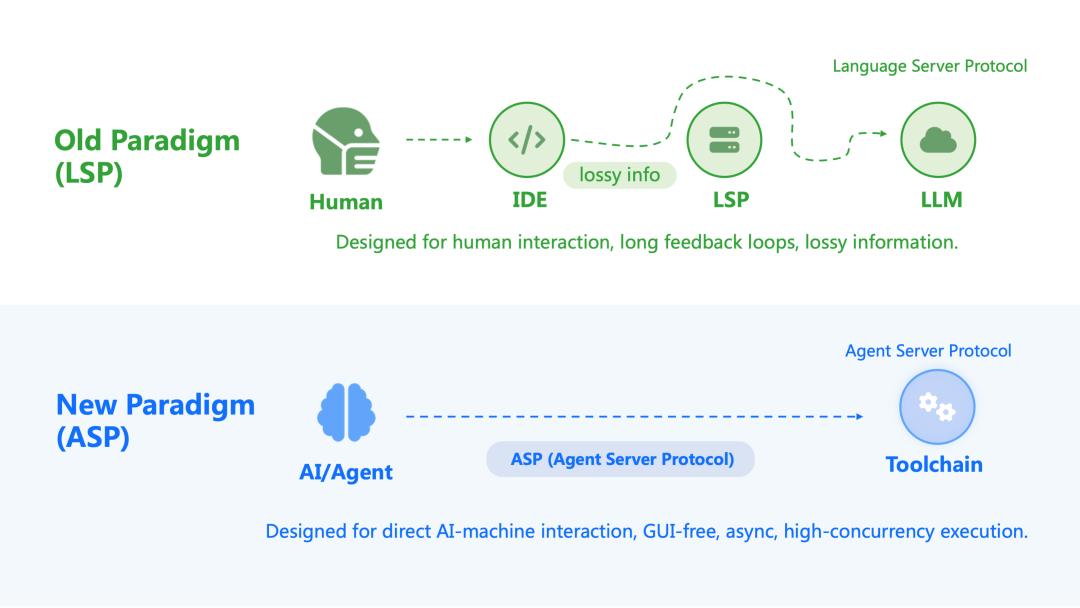
The workflow of traditional AI programming tools essentially revolves around human developers. Humans write prompts, models generate code, IDEs display results, and humans decide what to modify, what tests to run, and whether to submit. It appears automated, but the feedback loop remains “human → interface → model → human,” which is slow, has significant information loss, and is difficult to form a true closed loop. In this model, AI acts more like an assistant rather than a part of the engineering system.
The “MoonBit Software Factory” concept no longer assumes that there must be an “IDE layer for humans” in between. Instead, it directly exposes the capabilities to understand code, check structures, and run tests as programmatically callable interfaces. In other words, AI faces not a bunch of UI buttons but a set of engineering systems that can be directly interacted with. Once this interaction relationship is established, the rhythm changes completely: feedback is no longer “waiting for someone to click” but “immediately verifying after modification”; decisions are no longer “whether to continue writing” but “whether this modification passes constraints.”
Toolchain
The entire toolchain follows the “AI native” concept, designed specifically for agent optimization—debuggers, performance analyzers, coverage tools, and testing frameworks are all callable, significantly shortening feedback loops and improving reliability, thus avoiding low-level errors.
In this example, the AI agent can directly call the debugger to locate errors, use performance analysis tools to find hotspots, and utilize benchmark tests to prevent regressions while writing the C compiler (Fastcc.mbt). This sounds like a typical engineering process, but the key is that this entire process is completely smoothly callable by AI.
This explains a seemingly counterintuitive result: even without concurrency and using only one Codex agent throughout, the project still progressed from “running” to “optimizable” in ten days, with a speed about four times faster than clang - O0. The real determinant of speed here is not the generation throughput but the length of the verification feedback loop. Each round of modifications must go through compilation testing and repeated verification. This rhythm resembles pushing a production line in a software factory.
QuickCheck
QuickCheck is a groundbreaking implementation developed in 2000 by Koen Claessen and John Hughes for Haskell. It was the first tool to turn the idea of “automatically generating random test data to validate program properties” into a practical tool.
Property-Based Testing is the general name for the testing methodology represented by QuickCheck. The core idea is: you declare the “properties” that the code should satisfy (e.g., reverse(reverse(list)) == list), and the testing framework automatically generates a large number of random inputs to try to refute this property. This term now refers to all testing that adopts this method, not limited to Haskell or QuickCheck itself.
Fuzz Testing is a broader, older concept that originated in the security testing field in the late 1980s. Its core is to feed random or semi-random inputs to a program and observe whether it crashes or exhibits abnormal behavior. Traditional fuzzing does not necessarily have a clear “property” definition and often just checks whether the program crashes.
The transition from a software completion rate of 90% to 100% is aided by Fuzz Testing and Property-Based Testing. Failures like those of Cursor, which generated code quickly but uncontrollably, fundamentally stem from a lack of quality constraints that continuously pull results back onto the correct track. The reason the MoonBit software factory can advance projects from “running” to “usable, maintainable, and optimizable” lies in making quality verification an automatically executable gate, with the most effective type being QuickCheck / Property-based Testing.
Traditional unit testing is more like “giving examples”: I provide you with 10 inputs, expecting 10 outputs. Its coverage is quite limited and can easily be deceived by AI’s “appearing correct” outputs (hacking). Property testing is more like “writing rules”: rather than enumerating examples, it declares properties (invariants) that the program must always satisfy, and then the testing framework automatically generates massive random inputs to “crash into walls.” Once a counterexample is found, the framework will also automatically shrink the counterexample, reducing complex failure cases to the smallest, most reproducible, and locatable one, which is crucial for the agent: it receives not vague feedback of “something is wrong somewhere” but a reproducible, minimized, and stably reverting failure evidence.
This method is particularly effective in systems like compilers, PDFs, and spreadsheets (Excel), as they inherently possess many “structural equivalences / semantic invariants / round-trip consistency” properties that can be verified:
- Compilers: The same C code should yield consistent results across different compilers; optimizations should only allow for speed improvements without altering answers.
- PDF/Document Tools: Files should not suddenly deform or lose content when “opened → saved → reopened.”
- Spreadsheets/Excel: Formula calculation results should be stable; semantics should remain consistent before and after saving and loading; dependency relationships should not err (e.g., contradictory circular dependencies should not appear).
This testing forces AI to avoid relying on “confident outputs” for correctness, instead being compelled to iterate within a verifiable constraint system. Each modification must pass compilation, testing, and property checks; every performance optimization must proceed without violating properties, making the system increasingly capable of approaching truly reliable software during the verification process.
First Class Reasoning

MoonBit natively supports formal reasoning capabilities at the language level, which is another important defense for ensuring code correctness in the AI software factory.
Specifically, MoonBit allows developers (or AI) to annotate loops with loop invariants and supports writing semi-formal proof processes. This design has two key features:
- Executable Specifications: Loop invariants themselves are valid MoonBit code, not isolated comments or external annotations. In debug mode, these invariants are dynamically checked as runtime assertions—if violated, an error is immediately reported; in release mode, these checks are automatically removed, not affecting production performance. This “write once, two uses” design ensures strict verification during development while avoiding runtime overhead.
- AI Verifiable Proofs: The semi-formal proof process does not require complete formal proofs (which would be a significant burden for both AI and humans) but rather a structured description of reasoning steps. These proofs can be checked and completed using AI tools—AI can automatically generate candidate invariants and proof drafts based on the code and verify whether human or AI-written proofs are self-consistent.
The significance of this design for the AI software factory is that it transforms “code correctness” from a vague intuitive judgment into a checkable, iterable engineering constraint. When AI generates a segment of critical code with loops, it no longer relies solely on test cases for luck; instead, it can confirm the code’s behavior meets expectations through invariants and proof processes. This is especially crucial for software like compilers, which have high correctness requirements.
Conclusion
MoonBit currently supports three backends: WebAssembly (Wasm), JavaScript (JS), and Native. Notably, MoonBit has a clear advantage on WASM, possessing the most mature modules and excellent performance, allowing large software produced by the software factory to run efficiently in browsers. It also includes a sandbox and integrates a Wasm-based isolated runtime environment, enabling developers or AI application users to quickly deploy and test code without sacrificing security, making it suitable for building trustworthy AI-assisted development environments or edge computing scenarios. (The aforementioned C compiler also demonstrates a web version: https://moonbit-community.github.io/fastcc/)
MoonBit is driving software engineering from “manual coding” to a new era of “automated factories”: the human role will shift to defining requirements and making key decisions, while AI will handle construction and iteration within a rigorous engineering framework. As the ecosystem rapidly expands, MoonBit is not only a significant breakthrough for China in the AI programming language field but also holds the potential to reshape the foundational paradigm of global software production.
InfoQ, in collaboration with MoonBit, is launching a large software synthesis challenge:
The competition centers around the concept of an “AI native software factory,” exploring how to gradually transform the development process of complex software from a one-time implementation reliant on individual experience into a reusable, evolvable, and sustainable software engineering process based on the collaboration of large models with the MoonBit programming language and toolchain.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.