Introduction
The release of DeepSeek-V4 marks a new competitive phase for open-source large models. With its Pro and Flash configurations supporting 1M token context, it achieves performance breakthroughs through a revolutionary sparse attention mechanism. The technical report reveals its overwhelming performance in agent capabilities, world knowledge, and reasoning abilities, particularly excelling in Chinese writing scenarios compared to Gemini-3.1-Pro.

Model Configurations
DeepSeek V4 is available in two configurations:
- Pro: 1.6T total parameters, 49B active
- Flash: 284B total parameters, 13B active
Both configurations support 1M token context and are open-sourced, accompanied by a technical report.

Capabilities
V4-Pro has made significant advancements in four key areas:
Agent Capabilities
In the Agentic Coding evaluation, V4-Pro has reached the current best level among open-source models. DeepSeek has adopted V4 as its default coding model, with feedback indicating it outperforms Sonnet 4.5 and delivers quality close to Opus 4.6 in non-thinking mode, though there is still a gap in thinking mode. Specific optimizations have been made for mainstream agent products like Claude Code, OpenClaw, OpenCode, and CodeBuddy, enhancing performance in coding and document generation tasks.
World Knowledge
In knowledge assessments, Pro significantly outperforms other open-source models, only slightly behind Gemini-3.1-Pro. SimpleQA-Verified scored 57.9, surpassing Opus-4.6-Max’s 46.2 and GPT-5.4-xHigh’s 45.3.
Reasoning Performance
In evaluations for mathematics, STEM, and competitive coding, Pro exceeds all publicly evaluated open-source models and matches the performance of top-tier closed-source models. It achieved a LiveCodeBench Pass@1 of 93.5 and a Codeforces Rating of 3206, both the highest in the comparison group.
Long Text Processing
Pro excels in both synthetic benchmarks and real tasks at 1M tokens, outperforming Gemini-3.1-Pro in academic evaluations. It scored 83.5 in MRCR 1M and 62.0 in CorpusQA 1M.
The Flash model offers a different trade-off: it is more cost-effective, with slightly lower knowledge performance but comparable reasoning capabilities to Pro. In simpler agent tasks, its quality is on par with Pro, while for more complex tasks, Pro is preferred.
This tiered approach is similar to Claude’s Sonnet/Opus and GPT’s Mini/Pro.
1M Token Context as Standard
Previously, DeepSeek’s web version supported a maximum of 128K tokens, with 1M being a gray test. Starting today, 1M tokens will be the default context across all official services, including chat, API, web, and app.
This change is backed by a new attention mechanism.
V4 compresses tokens and adds DeepSeek’s own DSA sparse attention. As a result, under 1M context, V4-Pro’s single token reasoning FLOPs are only 27% of V3.2’s, and its KV cache is only 10% of V3.2’s. V4-Flash is even more extreme, with single token FLOPs at just 10% of V3.2’s and KV cache at 7%.
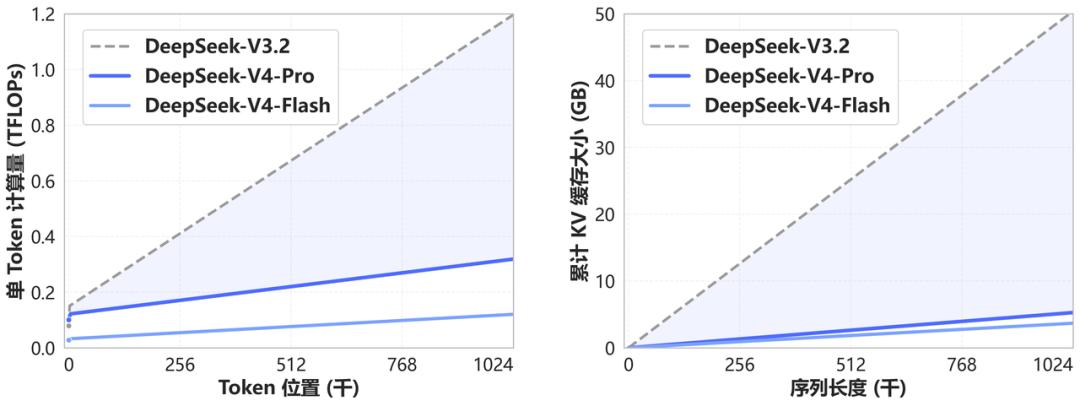
For one million tokens, it can easily accommodate the entire “Three-Body” trilogy, while also retaining all reasoning history in multi-turn dialogues, ensuring coherence in long-range agent tasks.

Architecture Overview
Let’s take a brief look at the architecture of DeepSeek V4. Don’t worry if you don’t understand it; there will be a mnemonic version later to help you explain it.
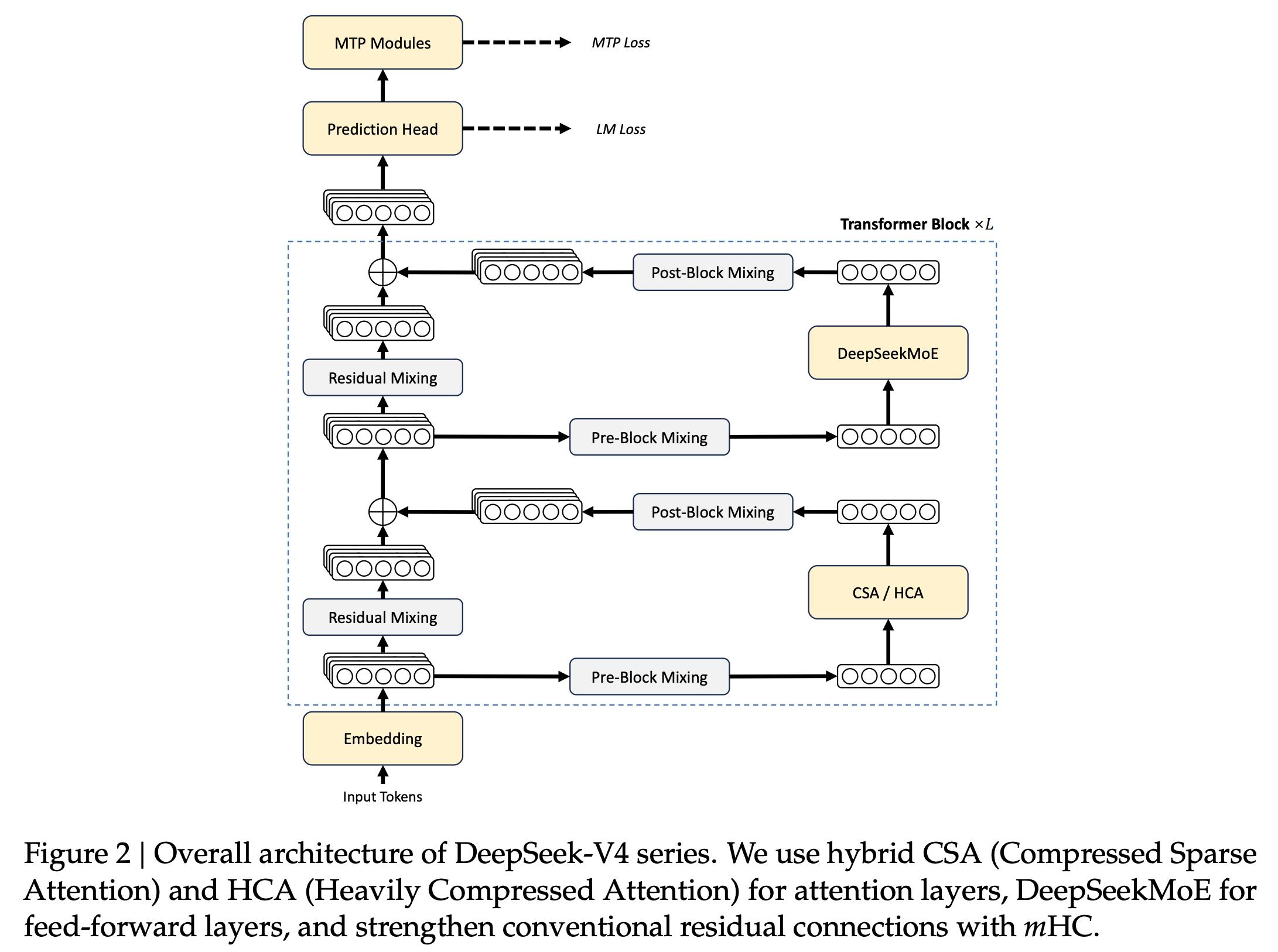
The V4 MoE framework builds on V3’s DeepSeekMoE, with three significant upgrades.
Hybrid Attention: CSA + HCA
Two types of attention layers are used in an interleaved manner:
- CSA (Compressed Sparse Attention): Each m tokens’ KV is compressed into one entry, followed by DSA sparse attention, where each query focuses on k compressed entries. In the Flash version, m=4, with 64 indexer query heads and a head dimension of 128, using sparse attention top-k=512.
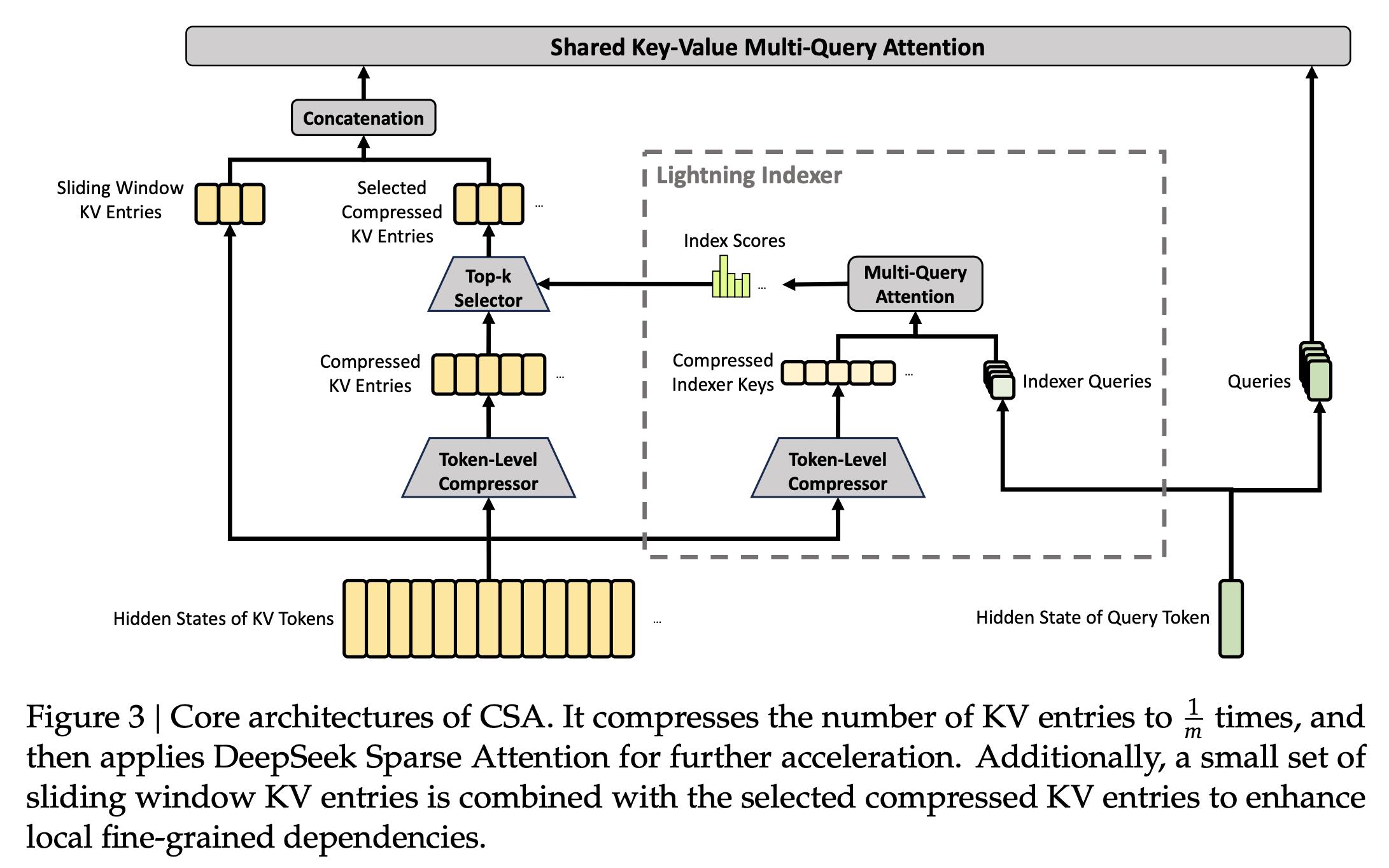
- HCA (Heavily Compressed Attention): This is more aggressive, compressing every m’ tokens into one, with m’ much larger than m (m’ = 128 in Flash). HCA does not perform sparse selection, maintaining dense attention.
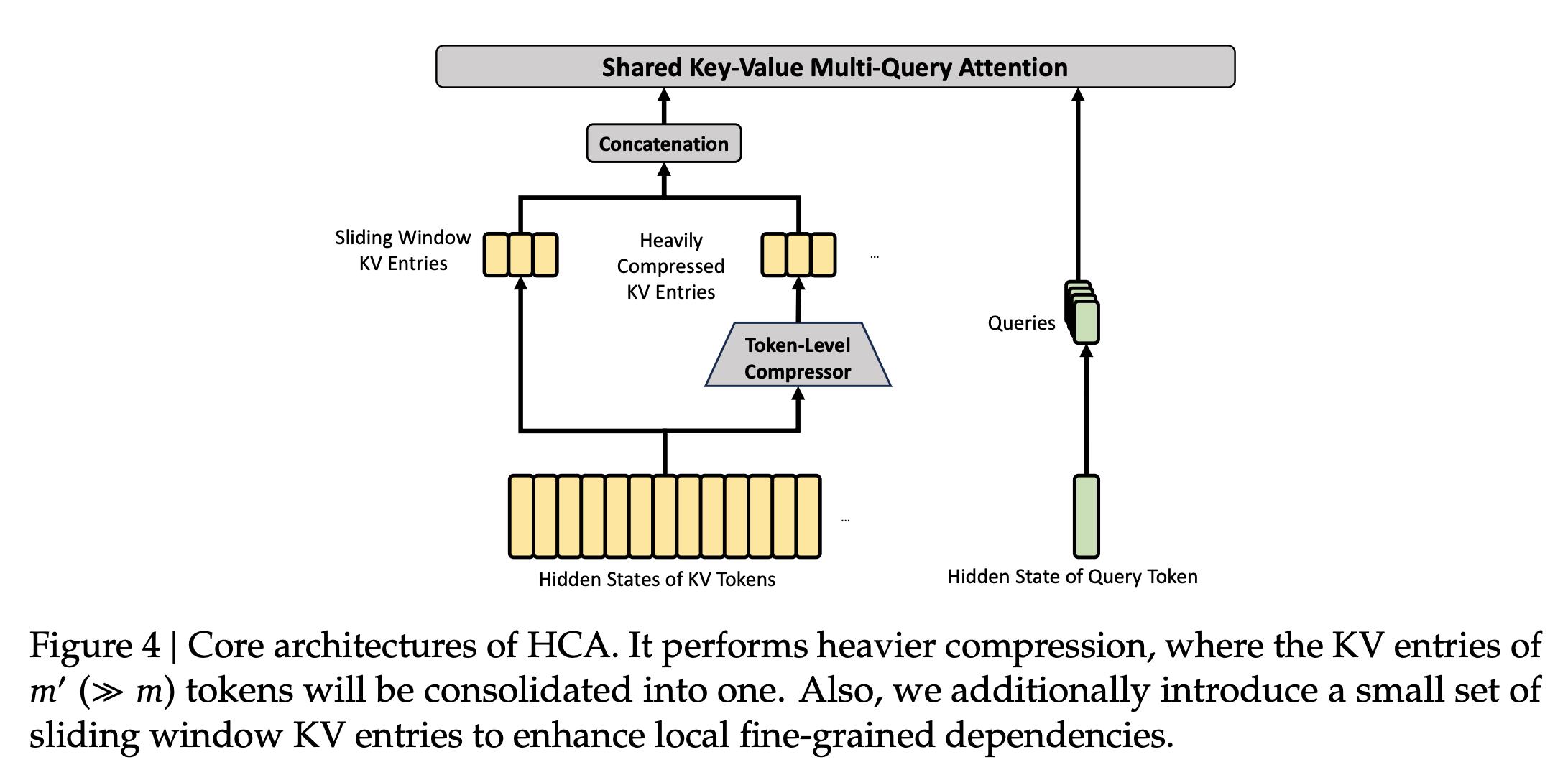
These two mechanisms manage both long-distance and ultra-long compression. In addition to the core structure, CSA and HCA share several details:
- The last 64 dimensions of query and KV entries are added with RoPE for partial rotary position encoding.
- Core attention uses attention sink techniques, adding learnable sink logits to each head.
- Each also has a sliding window attention branch to handle nearby tokens, avoiding loss of local dependencies due to compression.
mHC: Manifold-Constrained Hyper-Connections
mHC stands for Manifold-Constrained Hyper-Connections. It strengthens residual connections with manifold constraints, keeping the residual mapping matrix constrained to a double stochastic matrix manifold (Birkhoff polytope). This constraint ensures that the spectral norm of the mapping matrix is bounded, preventing non-expansive propagation even in deep stacks.
In implementation, mHC decouples the residual width and hidden size, controlling additional overhead with a much smaller expansion factor n (n=4 in V4). Parameters are dynamically generated, divided into input-related and input-independent parts, with the input-related part produced from the current token’s hidden state after RMSNorm. This is a result from a paper published by DeepSeek in January, marking its first application in a flagship model.
Muon Optimizer
DeepSeek has switched most module optimizers from AdamW to Muon. The embedding, prediction head, static bias, and RMSNorm retain AdamW, while the rest use Muon.
Muon’s core uses Newton-Schulz iteration for matrix orthogonalization. DeepSeek has improved upon the standard Newton-Schulz, calling it Hybrid Newton-Schulz. Coupled with the Nesterov trick and RMS rescaling, AdamW’s hyperparameters can be reused directly. This leads to faster convergence and better stability.
Additionally, while the MoE part inherits from V3, it has also been modified. The gating function has shifted from Sigmoid to Sqrt(Softplus), and the first few layers of dense FFN have been replaced with Hash routing MoE, with no limit on the number of routing target nodes, using auxiliary-loss-free load balancing and sequence-wise balance loss together. The Flash MoE configuration includes one shared expert and 256 routing experts, with 6 active per token and hidden dimension of 2048.
Training Overview
V4-Flash was pre-trained on 32T tokens, while V4-Pro was pre-trained on 33T tokens. Tokenization follows V3’s tokenizer, with a few special tokens added, maintaining a vocabulary of 128K. Document concatenation and Fill-in-Middle strategies are also inherited from V3, with sample-level attention masking.
In terms of precision, MoE routing expert parameters use FP4 precision, while most other parameters use FP8. This is the first time DeepSeek has fully run FP4 quantization-aware training on a flagship model. On current hardware, FP4 multiplied by FP8 achieves peak performance equivalent to FP8 multiplied by FP8, theoretically allowing new hardware to be 1/3 faster.
The training schedule starts with a sequence length of 4K, gradually expanding to 16K, 64K, and finally to 1M. The attention mechanism initially uses dense attention to warm up to 1T tokens, switching to sparse attention at 64K sequence length, and continues training. The batch size gradually increases to 75.5M tokens. The learning rate undergoes a linear warmup for 2000 steps, maintaining at 2.7×10⁻⁴ for most of the training, and finally decaying to 2.7×10⁻⁵ using cosine decay.
To enhance stability, two measures were taken. Anticipatory Routing decouples the synchronous updates of the backbone network and routing network, using the previous step’s network parameters to pre-calculate routing indices, avoiding loss spikes with minimal extra overhead. SwiGLU Clamping, borrowed from GPT-OSS, truncates SwiGLU outputs to eliminate outliers without sacrificing training performance.
In base model evaluations, V4-Flash-Base with 13B active has already matched or even surpassed V3.2-Base with 37B active on most tasks, demonstrating significant parameter efficiency.
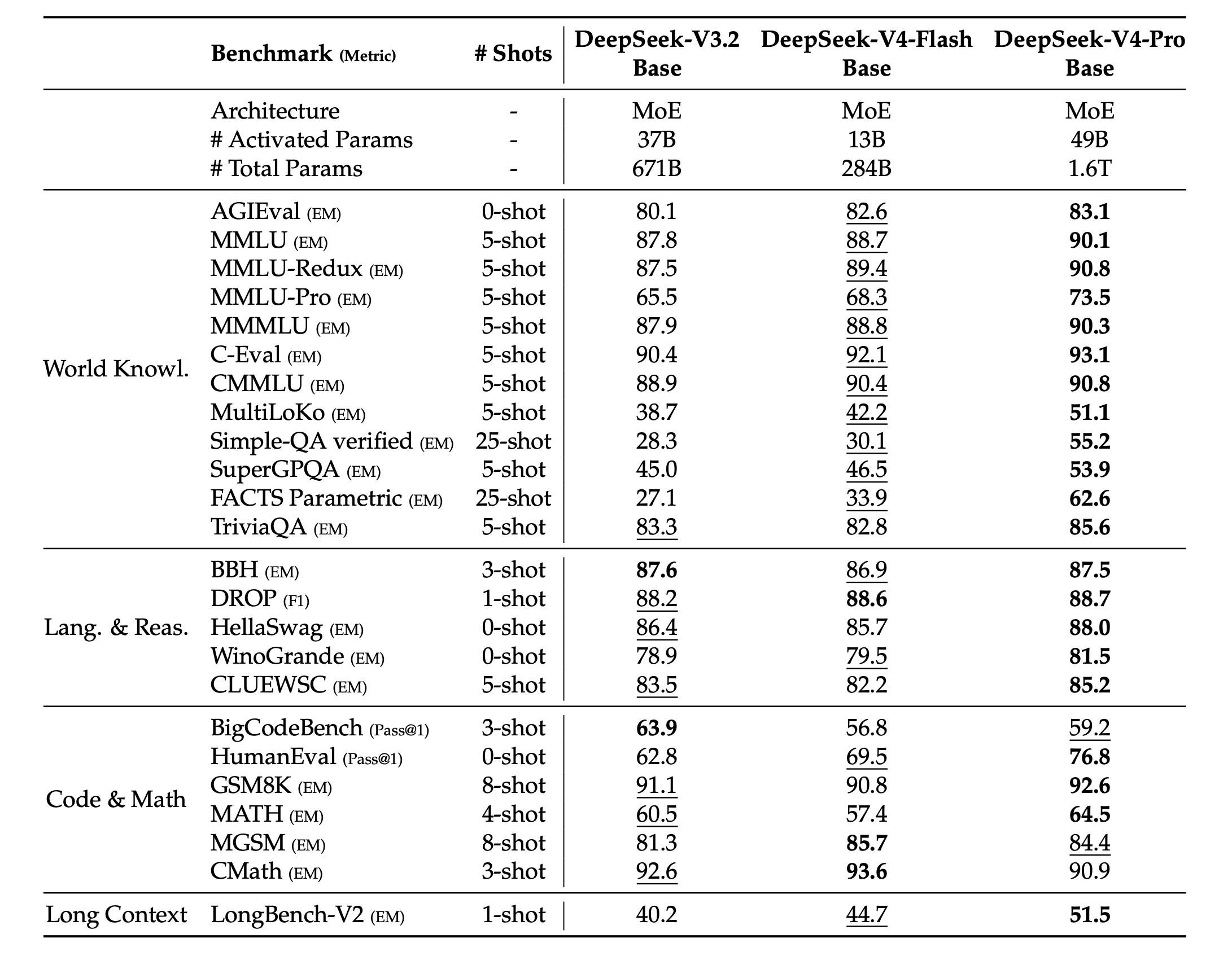
MMLU scored 88.7, MMLU-Redux 89.4, C-Eval 92.1, and CMMLU 90.4, all higher than V3.2-Base. In coding tasks, HumanEval Pass@1 achieved 69.5, surpassing V3.2-Base’s 62.8 by 7 points. V4-Pro-Base has significantly widened the gap in world knowledge, reasoning, coding, and long text processing compared to V4-Flash-Base, with Simple-QA verified scoring 55.2 and FACTS Parametric 62.6, more than double that of V3.2-Base.
Post-Training
V3.2’s post-training involved SFT plus mixed RL. V4 entirely replaced the mixed RL phase with On-Policy Distillation (OPD), which is the most crucial methodological shift in this post-training.
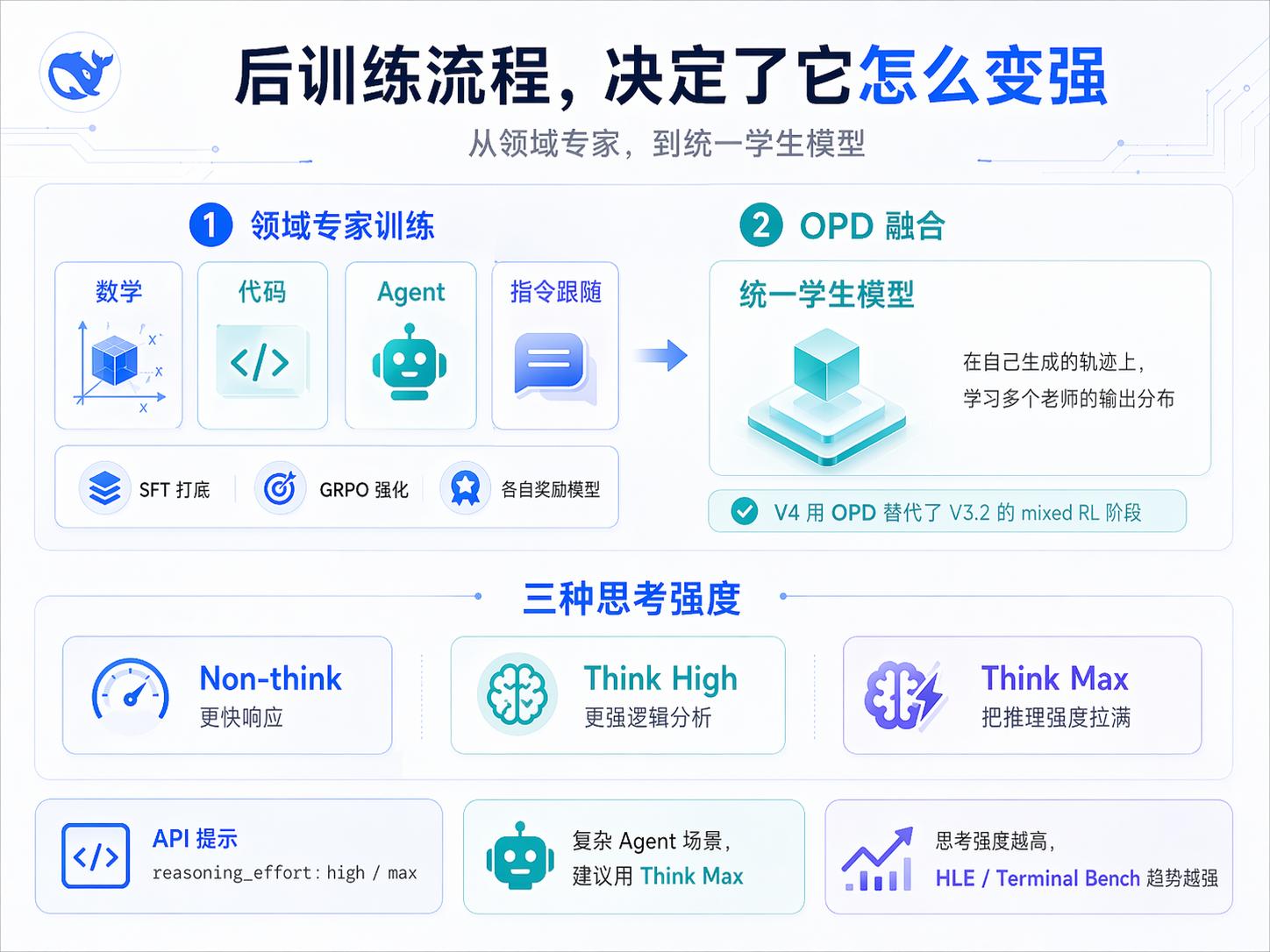
In the post-training phase, the overall process is divided into two steps:
- Specialist Training: Each target domain trains a separate expert model.
- On-Policy Distillation Fusion: All experts are merged into a single student model.
Step One: Specialist Training
Each domain follows the same two-step process: SFT as a foundation, followed by GRPO for RL, with each domain having its own reward model. Domains already trained include mathematics, coding, agents, and instruction following.
Each domain also trains three sub-versions with different reasoning intensities, corresponding to Non-think, Think High, and Think Max. These modes use different length penalties and context windows during RL training: Non-think uses a short context window, Think High uses 128K, and Think Max uses 384K, maximizing reasoning budget.
When training agent experts, a Quick Instruction mechanism was introduced. In chatbot products, there are many additional tasks, such as determining whether to trigger a search or recognizing intent. The traditional approach involves another small model handling these tasks, requiring re-prefilling each time. V4’s approach attaches a set of special tokens directly to the input sequence, with each token corresponding to an additional task, reusing the existing KV cache to eliminate redundant pre-filling and reduce first-token delay (TTFT).
Step Two: On-Policy Distillation Fusion
In the second step, all experts are merged into a student model. The method allows the student to learn the output distribution of multiple teacher models based on its generated trajectory. This paradigm is closer to the spirit of RL than traditional SFT distillation, as distribution matching is done on the state distribution under the student’s current policy.
To support OPD at a trillion scale, DeepSeek implemented several infrastructural enhancements. Teacher weights are centrally stored in a distributed storage system, loaded on demand, and sharded in a ZeRO style to reduce I/O and DRAM pressure. The logits for a vocabulary of over 100K cannot all be stored in full; only necessary parts are cached based on the student’s trajectory. Rollouts utilize FP4 quantization for acceleration, with services supporting preemption and fault tolerance, relying on token-level WAL and KV cache persistence to resume from breakpoints, avoiding length deviations from re-generation.
The RL for a million token context has also been optimized separately. Rollout data is divided into metadata and per-token layers, with metadata fully loaded for shuffling and packing, while per-token uses shared memory for lazy loading and immediate release after use, preventing memory accumulation on both CPU and GPU.
Agent training relies on a sandbox infrastructure called DSec. A unified interface abstracts differences between containers, microVMs, TTYs, etc., allowing a single cluster to handle hundreds of thousands of concurrent sandboxes. Images are loaded in layers via 3FS, starting in milliseconds. Each sandbox maintains a globally ordered trajectory log, recording every command and result. When training tasks are preempted, sandbox resources are not released, and upon recovery, it fast-forwards to the last breakpoint, avoiding repeated execution of non-idempotent operations.
Three Levels of Thinking Intensity
Both V4-Pro and V4-Flash support three levels of thinking intensity: Non-think, Think High, and Think Max.
- Non-think: Intuitive responses without deep thinking, used for everyday conversations and low-risk decisions. Returns format is empty plus summary.
- Think High: Conscious logical analysis, slower but accurate, used for complex issues and planning tasks. Returns format is thinking plus summary.
- Think Max: Pushes reasoning intensity to the limit, exploring the model’s reasoning capabilities. Requires a special system prompt to trigger. Returns format is the same as Think High.
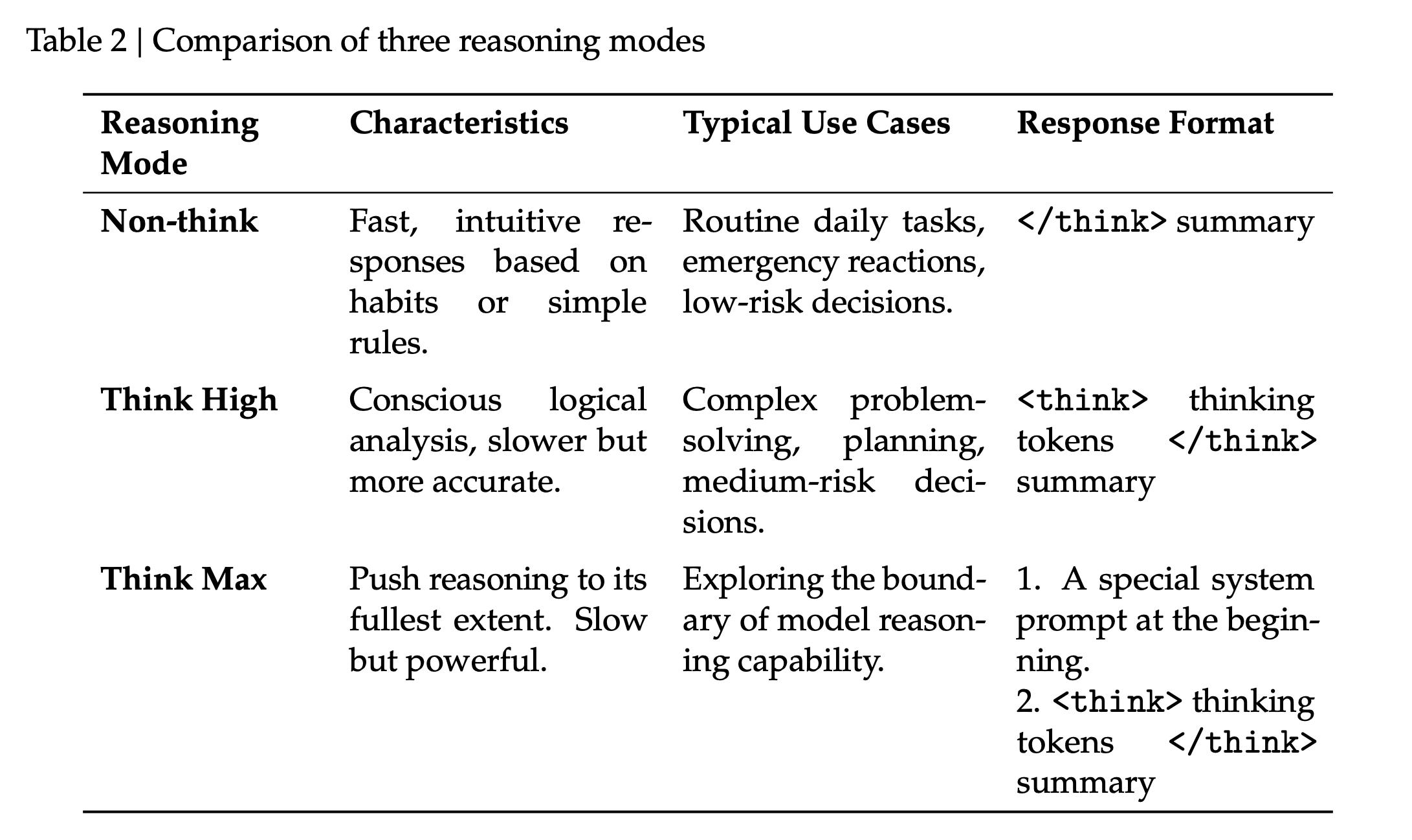
However, Flash-Max can approach Pro-High in most tasks. When budgets are tight, Flash is sufficient, while Pro is reserved for critical tasks.
Another change from V3.2 to V4 is how thinking content is handled:
- V3.2 discarded thinking traces at the start of each new user message.
- V4 retains all reasoning content in tool calling scenarios, including across user message boundaries.
This improvement directly aids the coherence of long-range agent tasks, allowing the model to maintain a complete chain of accumulated thought across multiple calls.
Infrastructure Focus
The technical report dedicates an entire chapter to “Infrastructure,” weighing as much as architecture and training.

Fine-Grained Expert Parallel Communication
DeepSeek’s self-rewritten DeepGEMM has introduced the mega-kernel MegaMoE, achieving acceleration of 1.50 to 1.73 times compared to strong baselines for general reasoning, and up to 1.96 times for small batch long-tail scenarios.

This kernel has been validated on both NVIDIA GPUs and Huawei Ascend NPUs and is now open-sourced.
Kernel Development
The transition from CUDA/Triton to the open-source TileLang from Peking University has been made. TileLang moves most host-side logic to generated code using Host Codegen, reducing CPU-side validation overhead from hundreds of microseconds to a low level. TileLang also provides IEEE-compliant numerical primitives and precise layout annotations, achieving bit-level consistency with hand-written CUDA.
Deterministic Kernel Library
All kernels have achieved batch invariance and determinism. The output bits remain consistent regardless of the token’s position in the batch, and the same input produces consistent outputs across two runs. These features are beneficial for debugging, stability analysis, and post-training consistency. Bit alignment can be achieved across pre-training, post-training, and inference pipelines.
FP4 Quantization-Aware Training
The FP8 mixed precision framework largely follows V3, without altering the backward flow. FP4 uses simulated quantization: during the forward pass, FP8 master weights are quantized to FP4, while gradients are directly passed to FP32 master weights during the backward pass, equivalent to a Straight-Through Estimator (STE) quantization operator. Inference and RL rollout phases use true FP4 weights directly, saving memory and accelerating performance.
Muon Engineering Implementation
Muon requires a complete gradient matrix for parameter updates, conflicting with ZeRO’s element-wise partitioning. DeepSeek designed a hybrid ZeRO bucket allocation strategy, balancing dense parameters and using a knapsack algorithm for load balancing. The overall system runs smoothly without sacrificing parallelism.
On-Disk KV Cache
The KV cache management for the inference framework has been redesigned. The heterogeneous KV entries of CSA and HCA, along with the additional dimensions introduced by sparse selection, necessitated a dedicated KV cache layout, divided into state cache (SWA + uncompressed tail) and classical KV cache (compressed entries of CSA and HCA). For storage, all compressed entries of CSA and HCA are stored on disk, reused upon request hits; SWA, being about 8 times larger than compressed entries, offers three caching strategies: full cache, periodic checkpointing, or zero cache with recomputation.
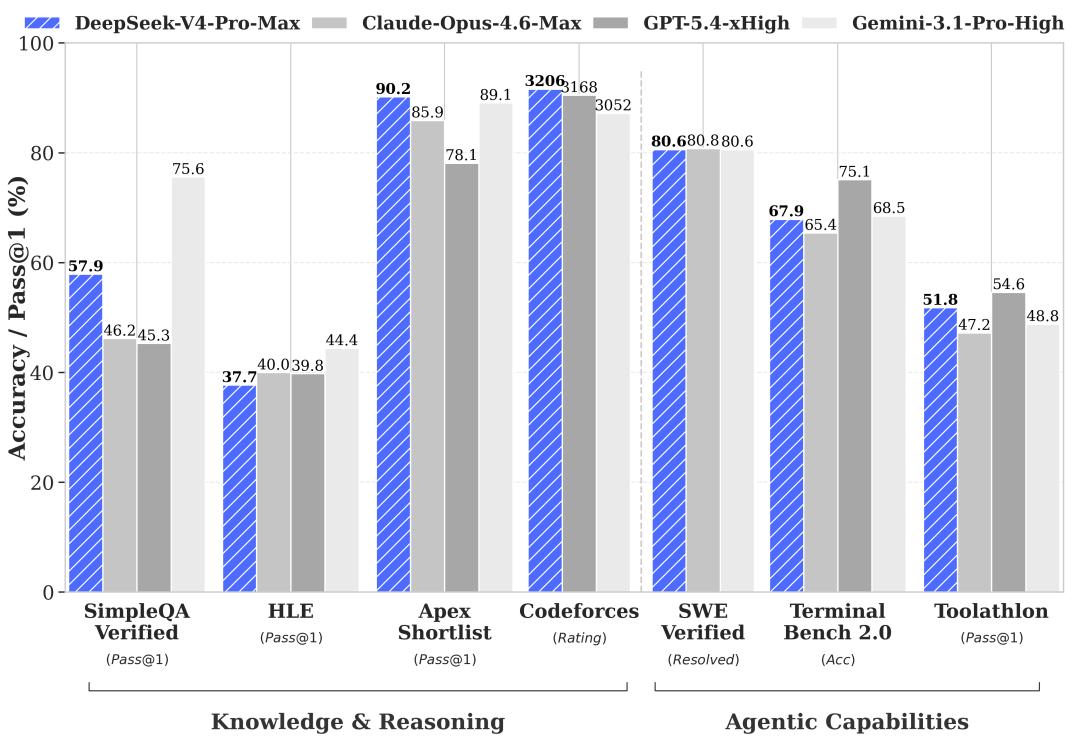
Performance Overview: Where V4-Pro-Max Stands
Comparative benchmarks are made against V4-Pro-Max, with competitors including Opus-4.6-Max, GPT-5.4-xHigh, Gemini-3.1-Pro-High, K2.6-Thinking, and GLM-5.1-Thinking, covering both open-source and closed-source top positions.
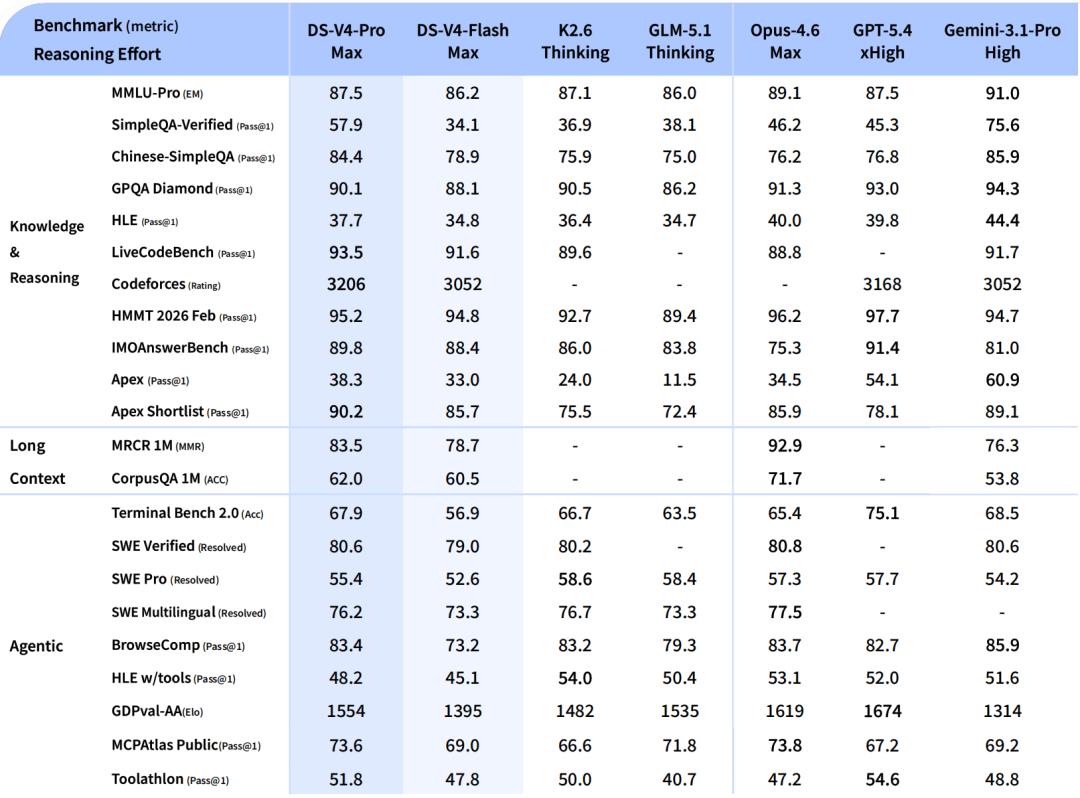
Coding Performance
LiveCodeBench Pass@1 scored 93.5, Codeforces Rating 3206, and Apex Shortlist 90.2, all the highest in the comparison group. The Codeforces score of 3206 slightly surpasses GPT-5.4-xHigh’s 3168.
Knowledge Performance
MMLU-Pro scored 87.5, close to the median in the comparison group, while SimpleQA-Verified scored 57.9, higher than all models except Gemini. Chinese-SimpleQA scored 84.4, close to Gemini’s 85.9. HLE scored 37.7, significantly lower than Gemini’s 44.4, marking the most noticeable shortcoming.
Agent Performance
Terminal Bench 2.0 scored 67.9, SWE Verified 80.6, SWE Multilingual 76.2, and MCPAtlas 73.6, overall aligning with Opus-4.6-Max and K2.6-Thinking. GDPval-AA scored 1554, trailing GPT-5.4-xHigh’s 1674.
Long Text Performance
MRCR 1M scored 83.5, and CorpusQA 1M scored 62.0. While it surpassed Gemini-3.1-Pro’s 76.3 in MRCR, it still lags behind Opus-4.6’s 92.9. Similarly, Opus leads in CorpusQA. Within the 128K range, V4’s retrieval performance is very stable, but it begins to decline beyond 128K while remaining competitive.
In mathematics and formal reasoning, HMMT 2026 Feb scored 95.2, and IMOAnswerBench scored 89.8. On Putnam-2025, it achieved a perfect score of 120/120 using hybrid formal-informal reasoning, compared to Aristotle’s 100/120, Seed-1.5-Prover’s 110/120, and Axiom’s 120/120.
In the 1M long context MRCR 8-needle evaluation, V4-Pro-Max scored 0.94 within 8K, 0.92 at 128K, maintaining 0.85 at 512K, and dropping to 0.66 at 1M, still the most stable open-source model in its class. Flash-Max performs comparably to Pro within 128K, but declines faster beyond that. This indicates that V4 retains information well in real workflows under medium lengths (below 200K), with concerns only at extreme scenarios (512K+).
Real Task Performance
Beyond benchmarks, V4 has undergone comparisons in several real tasks.

Chinese Writing
This is one of the most commonly used scenarios by DeepSeek users.
V4-Pro’s win rate over Gemini-3.1-Pro in functional writing is 62.7%, while Gemini’s is 34.1%. The explanation for Gemini is that it often adds unnecessary elements in Chinese writing, overshadowing explicit user requests.
In creative writing, V4-Pro has a 60.0% win rate in instruction following and a 77.5% win rate in writing quality. However, in the most challenging multi-turn constrained writing, Opus 4.5 still has a 52.0% advantage over 45.9%.
Search
One of the core capabilities of chatbots. Non-think uses RAG, while Thinking employs Agentic Search. In pairwise evaluations, V4-Pro significantly outperformed V3.2 in both objective and subjective Q&A, with the greatest advantage in single-value retrieval and planning & strategy tasks.
In comparison and recommendation tasks, V3.2 still holds competitive ground. Agentic Search clearly leads over RAG in complex tasks, with costs only slightly higher than RAG.
White-Collar Tasks
In 30 advanced Chinese professional tasks, including analysis, generation, and editing.
V4-Pro-Max achieved an overall win rate of 53% against Opus-4.6-Max, with 10% ties and 37% losses.
In terms of dimensions, task completion was 96.68, higher than Opus’s 88.88, content quality was 87.76, close to Opus, instruction following was 84.06, slightly lower than Opus, and aesthetic formatting was 72.68, which lags behind Opus’s 86.52, especially in visual presentation for PPT tasks.
V4-Pro generated PPT slides under the agent framework, showcasing a complete marketing plan.
Code Agent
From over 50 internal engineers’ daily work, 30 real R&D tasks were sampled, covering various tech stacks like PyTorch, CUDA, Rust, and C++. V4-Pro-Max achieved a pass rate of 67%, higher than Sonnet 4.5’s 47%, close to Opus 4.5’s 70% and Opus 4.5 Thinking’s 73%, but lower than Opus 4.6 Thinking’s 80%. When asked if V4-Pro could serve as their primary coding model, 52% of 85 DeepSeek employees said yes, 39% leaned towards yes, and less than 9% said no. Feedback highlighted shortcomings in minor errors, interpreting vague prompts, and occasional overthinking.
Overall, V4 has made significant strides in Chinese writing, professional documentation, and coding engineering, which are the most common scenarios for DeepSeek users. The main shortcomings lie in tasks requiring aesthetic formatting, such as PPT visual presentations, and in the most complex multi-turn coding scenarios, where Opus still holds an advantage.
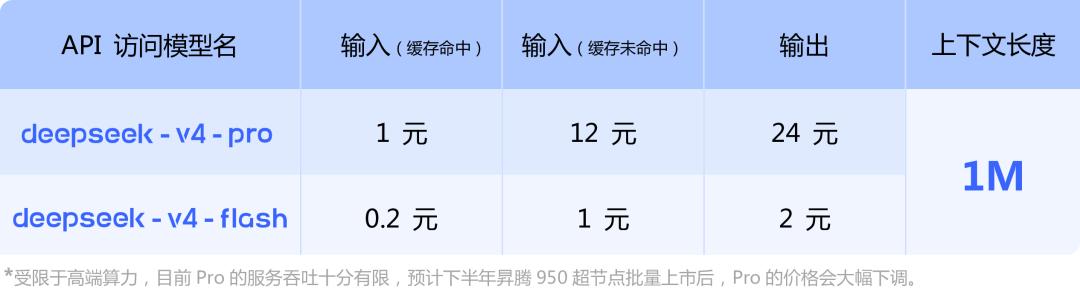
API Usage
New model names: deepseek-v4-pro and deepseek-v4-flash, with the base URL remaining unchanged.
Interface compatibility: Supports both OpenAI ChatCompletions and Anthropic interface standards.
Thinking mode: Set thinking.type to enabled or disabled, with the default being enabled.
Thinking intensity: reasoning_effort can be set to high or max. For ordinary requests, the default is high, while complex agent requests like Claude Code and OpenCode automatically elevate to max. For compatibility, low and medium map to high, and xhigh maps to max.
Transition from old model names: deepseek-chat and deepseek-reasoner will be discontinued on July 24, 2026 (three months from now). During the transition period, these two names will point to the non-thinking mode and thinking mode of deepseek-v4-flash, respectively.
Pricing: V4-Pro charges 1 RMB per million tokens for cache hits, 12 RMB for misses, and 24 RMB for output. V4-Flash corresponds to 0.2 RMB / 1 RMB / 2 RMB.
A note at the bottom of the pricing table mentions that due to high-end computational limits, the Pro service’s throughput is currently very limited, and prices are expected to drop significantly later this year after the release of the Ascend 950 super nodes.
Availability
The web chat at chat.deepseek.com or the official app allows for direct conversations. The API can be accessed by changing the model parameter. Open-source weights are available on HuggingFace and ModelScope under the MIT license, with separate Base and instruct versions for Pro/Flash.
For local deployment, it is recommended to set sampling parameters to temperature=1.0 and top_p=1.0. The Think Max mode suggests a minimum context window of 384K. This time, the chat template is not provided in Jinja format; instead, an independent encoding module is included, containing Python scripts and test cases to encode the OpenAI compatible format into model input strings and parse model outputs.
At the end of the technical report, DeepSeek also outlines future directions:
- Even sparser embedding modules
- Low-latency architecture
- Long-range multi-turn agent tasks
- Multimodal support

Additionally, DeepSeek V4 currently does not support multimodal reference materials.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.